Hour 18: Pages not getting indexed!
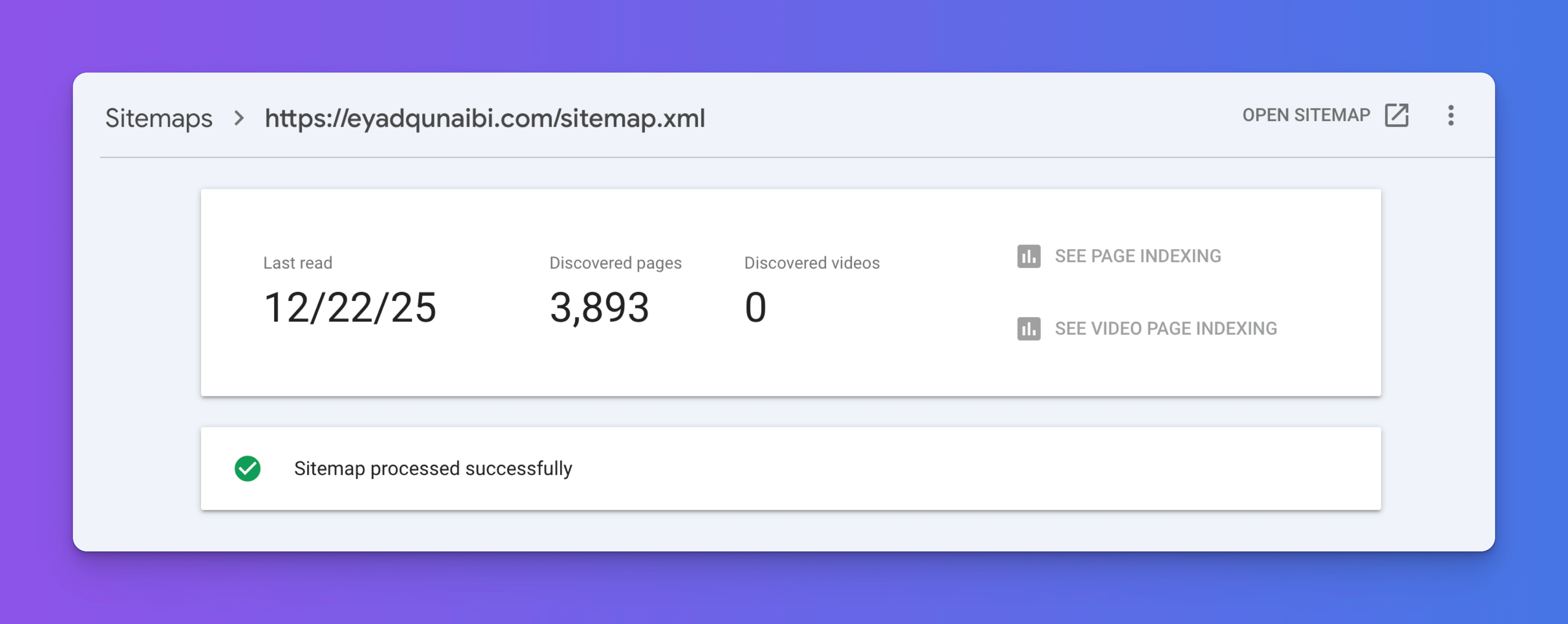
ok so it's been a few days since i submitted the new sitemap.xml via the Google Search Console.
Personal Transmissions
ok so it's been a few days since i submitted the new sitemap.xml via the Google Search Console.
we're finally live, but this is just the beginning..
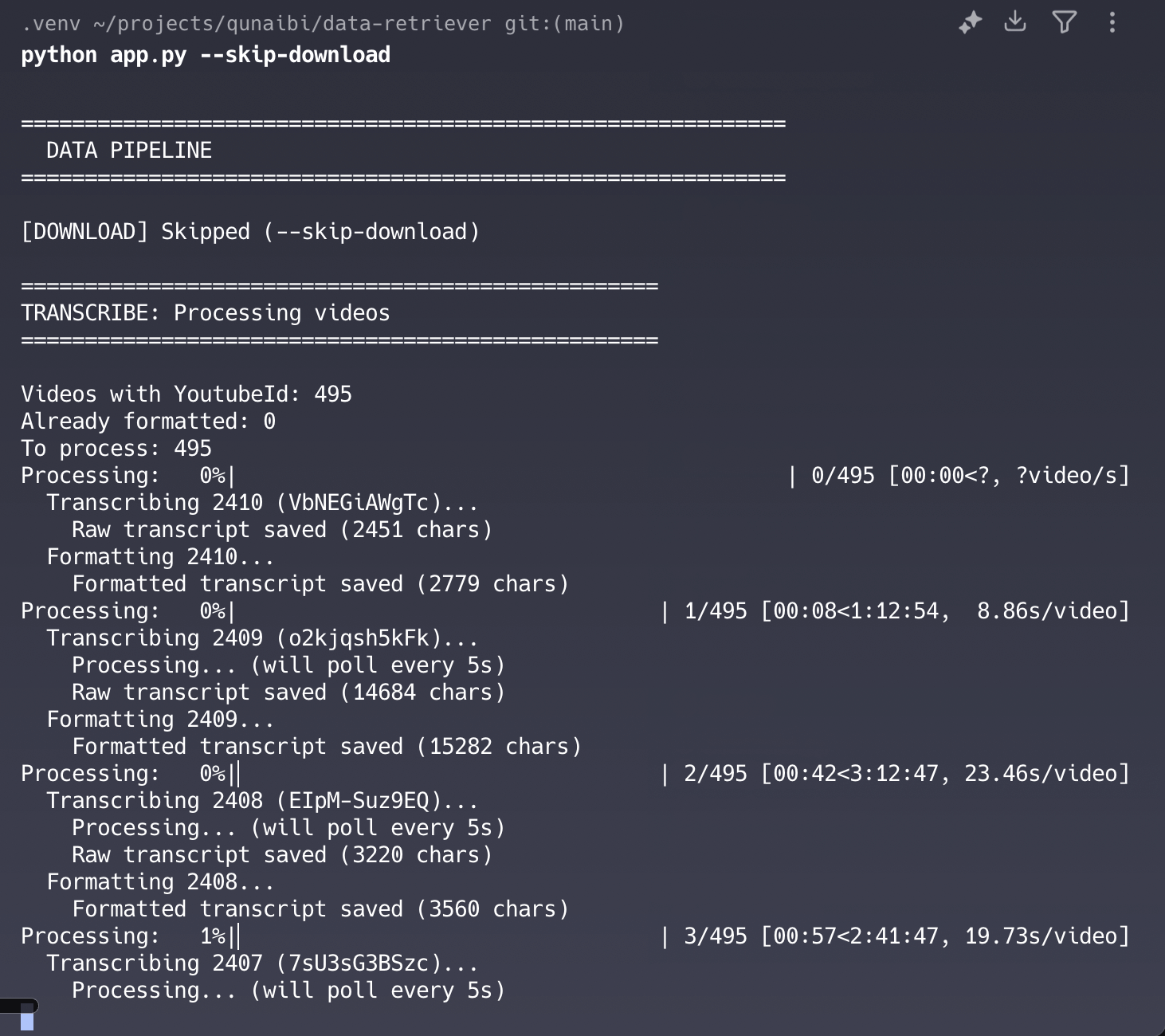
Okay, so last time tried to translate all of the content from Arabic to English and French. I really wanted to get this working directly from inside Claude Code (using my Max subscription instead of paying for API usage), but whatever -- it didn't work.
Today, we'll fire up a script and get the job done for shizzle.
I initially thought that I'd need to create some sort of custom workflow to get this done. But having recently upgraded to the $200/mo Max plan on Claude Code, I thought it worthwhile having claude take a stab at translating the .jsonl files directly.
I wasn't sure what to expect, since these files are BIG. I mean, the largest one clocked in at 4.5MB of pure text!
Came across this codepen which gave me an idea:
https://codepen.io/l3dlp/pen/PJyNdx
What if the whole thing was pixelated, like an indie game vibe?
Now working on a minimal UI where the main core screen shows the voxelated heart in the middle.
Ok, made it rotate about the y-axis. but didn't get any of hte mechanics sorted yet! i should do that next.
(wasted 30 mins so far doing this!)
So we're going to be updating the website at eyadqunaibi.com, and I'm using Claude Code with the front-end UI skill to do it.
I've been using this for a while now, and it's done a phenomenal job so far -- including with updating this very site! So I'll have it completely reimagine what the entire site is going to look like.
Ok so my original plan - way back when - was to create a completely new website that I can use to host the SEO optimized content in Q&A form, based on the terms that people search for.
Then, it occured to me.
Now that we've retrieved all the content, it's time to figure out how we can use that information to answer questions people are seeking answers to via Google.
Okay, the general idea here is that we're going to be converting all of the content that we have into text.
In my last entry, I shared that I'd finally managed to figure out the API powering the Eyad Qunaibi app. Today, I'll retrieve all the content, and save it locally.
We'll then figure out a way to use AI to map that to questions people are seeking answers to via Google, and then create those answers based on the entire corpus of materials. This'll be fun!
Ok this is getting ridiculous. It shouldn't be this hard getting the content from an app!
Alas, I'm close!
Ok, I still need to figure out how to get the content from the mobile app! This is such a big deal, because it'd just simplify everything downstream.
I mean, there's a mobile app that has access to 2,500+ pieces of content -- that i'd otherwise have to compile by hand. Why wouldn't I want to take advantage of that??
It's been a month since I last did anything about this series. I'm hoping I can be more consistent this time around!
In my last post, I was trying to figure out how to get the content from the mobile app.
I'd heard about ChatGPT releasing better memory and the ability to query past chats. I didn't think much of it at the time. Maybe this would be useful for looking up things I'd asked in the past and following up on them. But it was pretty vague, and I didn't have any deep thoughts on the matter.
Then I spotted a tweet. Someone asked ChatGPT to uncover what his top blind spots were. I thought, "Hey, let me try that!" I've had hundreds of conversations with ChatGPT over the past couple years, so there's probably something there.
I was completely floored by GPT's response. It was 100% on point. Many things I'd kind of felt on and off over the years but never quite articulated were right there in front of me - and ranked too!
I want to share them below and start a journey to improve each of the five points it highlighted. These are massive. If I can get better at these five things, I'll become so much more effective.
At the end of the day, there are certain things I'm good at and certain things I'm bad at. To become more well-rounded, you want to address the things you're absolutely bad at. Even if you just reach a competent level, that's enough of a boost to make you 10x more likely to succeed.
That's really what this post boils down to: uncovering all five blind spots, sharing my opinions on them, and later coming up with a plan to address each one.
Symptoms:
Blind Spot: You know marketing is crucial—but you undervalue its importance relative to product building. You treat it like a side task, even though it's the core engine of user growth.
Impact: You ship great products that barely see daylight. You're relying too much on organic reach or delayed launches, leading to lost momentum and weak customer traction.
Fix: Systematize it like you would engineering—timebox, templatize, and delegate. Or partner with someone who lives for attention.
Symptoms:
Blind Spot: You're optimizing for scalability and polish before proving the concept is wanted. You think like a craftsman, not a scrappy experimenter.
Impact: You miss fast validation loops. Ideas take weeks or months to test that could've taken days. When they flop, it's a heavy emotional and time cost.
Fix: Adopt a "10% solution" rule: build only what's necessary to test one core user behavior. Fight the urge to polish. Be ugly and fast.
Symptoms:
Blind Spot: You're delegating tasks but not outcomes. You want to trust people to self-manage but haven't built a system that guarantees visibility and follow-through.
Impact: You burn time reviewing others' work. You become the fallback for quality. Morale and performance stagnate on your team.
Fix: Set up weekly outcome-based reviews: not "did you do the task?" but "did the user outcome improve?" Use a single source of truth, kill passive tools, and implement weekly reporting with sharp, non-negotiable KPIs.
Symptoms:
Blind Spot: You see storytelling as indulgent or self-promotional. But your background, conviction, and faith alignment are major trust signals—especially in Muslim markets.
Impact: You're missing out on magnetizing early adopters and believers. You seem more like a tool than a movement.
Fix: Start weaving your story into everything: your landing pages, your video intros, your about page. Frame it as "why I had to build this" rather than "look at me."
Symptoms:
Blind Spot: You frame perfectionism as thoughtfulness. But often, it's fear of being wrong. You stall instead of launching the imperfect version and iterating.
Impact: It creates decision fatigue. You never feel like you're on solid ground, even when you are. Your velocity drops.
Fix: Set "imperfect by design" constraints—e.g., "launch within 72 hours or kill it." Keep a kill-switch journal for stalled ideas. Track decisions by speed, not just by quality.
Okay, let's take stock of where we're at.
Okay, let's see if we can find any other content sources for Eyad Qunaibi.
Okay, let's hit the first task on the list:
Okay, it's 8:30 p.m. I just set the timer for an hour. What am I going to do? I mean, it's kind of intimidating to think about what I could possibly do that could impact Gaza in any way. But I think it's helpful to just step back and think about the bigger picture.
Would I actually go to Gaza? The question haunts me. Not that I have the means right now, but what if I did? What if the borders were open, and the option was there? Part of me asks, 'Why wouldn't I?' Wouldn't I lay down my life to stop a child or a mother from being killed?
But would I actually? The best way to answer a hypothetical like this is to look at the track record. What have I really done for Gaza so far? That's the clearest indicator of what I might do if circumstances allowed.
Maybe I'm approaching this wrong. The question isn't necessarily about physically going there—it's about what part of my life I'm willing to give to this cause.
Our time is our life. It's the most valuable, non-renewable resource we possess. So perhaps the real question is: what portion of my life am I willing to dedicate to Gaza?
When viewed this way, dedicating structured time becomes a tangible form of giving a piece of my life away. Not all at once; but consistently and meaningfully.
So I'm starting here: dedicating one hour of each weekday to Gaza.
Carve it out. Protect it. Make it sacred.
I don't know exactly what I'll do in that time or the impact it might have, but it's a concrete piece of my life I'm committing. A smaller version of "going to Gaza" that I can actually fulfill right now.
Hopefully, it's something I can build on.
Muslims, do not make your question: 'Will this or that change in my life stop what is happening in Gaza?' Rather, let your question be: 'Have I offered through it what I can and proven that I want to support Islam and its people?'
ما يحدث يلين الحجر...قصف مراكز الإيواء والخيام المهترئة، حرق المراكز الطبية بمن فيها، المزيد من الناس في العراء بلا مأوى ولا طعام ولا علاج. كم نحن خاسرون إذا مرت الأيام على مجازر غزة ونحن عاجزون -لا عن نصرة إخواننا فحسب- بل وعن أن نوظف هذه الأحداث لتُحدث ثورة في تفكيرنا وسلوكنا
Most people search for domain names the wrong way. They start with an idea generator, check domain availability, and when their perfect .com is taken, they either:
I've found a better way.
There's a better approach. Every day, tens of thousands of domains expire and get dropped because:
While many dropped domains are worthless, some are gems. Finding them is like finding a needle in a haystack, but the advantages are significant:
The main challenge is filtering through thousands of domains. Some domain connoisseurs spend hours daily reviewing domain lists - I'm not one of those people.
Here's the strategy I developed:
Take all available dropped domains
Apply basic filters:
.com)Feed the filtered list (still thousands) into an LLM with specific criteria like:
Get notified when domains matching your criteria become available
Here's a killer strategy that's often overlooked: searching for domains that transliterate to Arabic words. I've previously sold shoghol.com for $1,500 using this approach.
Recent catches using this filter, all at basic registration price ($13):
istighfar.com - means "seeking forgiveness" in Arabicmroor.com - means "traffic" in Arabicwkala.com - means "delegation" in Arabicghoroob.com = means "sunset" in ArabicI've packaged this entire system into a service that lets you enter your own filters and get notified when domains matching your criteria become available. It's already helped me snag these and many other great domains for dirt cheap.
Note: I'll update this post with example domains once I have permission to share them.
I have a long list of ideas for things that I want to work on. A list that I will hopefully share at some point. But the core idea is that the best way to work through a list of ideas would have been to dedicate a solid chunk of time to actually implementing it. They become bigger events, there's a certain amount of work that needs to be done. That's typically a matter of days, weeks, possibly even months depending on the size of the project.
So it needs to clear a high bar before it can get my attention. And a lot of ideas just fall at the bar or even below and so they don't really pass they just stay lingering in a to do list that just keeps growing with time.
But now with AI and you know the availability of tools like Cursor and Lovable and others it's actually become a lot easier to build and launch projects and test them to see if they actually work. And of course this puts pressure on distribution for you to figure out like how you're actually going to grow a tool and that's something I'm still trying to figure out but we'll get to that later.
I'm going to be doing a bunch of experiments with distribution to figure out like how to do that effectively but right now the sort of focus for the first half of this year is how do we get more stuff done? How do you publish more?
On February 2nd, I woke up to my highest weight ever: 85.1 kilograms. Something clicked. Instead of setting a grand goal, I remembered advice from "Mini Habits" and "Atomic Habits" - start with tiny, daily habits that are impossible to fail.
i'm currently 85kg, the heaviest i've ever been. i'd like to drop 10kg in the next 3 months. starting this thread to track my weekly progress. i'll be asking myself 1 simple question, each day: "did i feel hungry today" yes = ✅ no =❌

I chose one simple question: "Was I hungry today?"
That's it. No diet plans. No calorie counting. Just checking if I felt genuine hunger at any point during the day.
Nine weeks in, I've lost nine kilograms - exceeding my initial expectations. But the real win isn't the weight loss. It's the fundamental shift in how I relate to food.
Before, hunger was an annoyance to silence immediately. Now, feeling hungry feels like winning. My baseline has shifted - I aim to maintain a slight hunger throughout the day rather than constantly feeling full.
Take ice cream: I used to eat two or three a day without thinking. I'd just eat them, feel a momentary sense of relief, and then go back to some sort of baseline. Now I have one in my fridge for two and a half weeks, untouched. Not because I'm resisting temptation, but because I don't crave it anymore. My satisfaction comes from feeling light and slightly hungry.
This attempt feels fundamentally different from my previous weight loss attempts. Before, I was always working towards a goal - a number on the scale or a deadline. Once I hit that goal, I'd inevitably bounce back to my old habits. But this time, I'm not working towards an endpoint. I've changed my relationship with food itself.
The key difference is that I'm not resisting temptation or forcing myself to change. Instead, I've rewired what gives me satisfaction. Feeling slightly hungry throughout the day has become my new normal, and it feels good. I don't see this as a temporary state to endure until I hit some target weight - it's just how I live now.
This experience made me wonder: what other improvements could I make by focusing on systems rather than goals? As Scott Adams puts it in "How to Fail at Almost Everything and Still Win Big": "If you do something every day, it's a system. If you're waiting to achieve it someday in the future, it's a goal."
Now that I've established this new relationship with food, I'm curious about applying the same systems-based approach to building muscle. Instead of setting ambitious lifting goals or following complex workout plans, I'm starting with one simple question: "Did I train one muscle group to failure today?"
I'll report back in a few months on how this experiment goes. But if the weight loss journey taught me anything, it's that the key isn't in the grand plans - it's in the tiny, daily habits that reshape how you think about the whole endeavor.
Take off your snowshoes
Every few days I come across people on the same trails trudging slowly with snowshoes and hiking poles. They’re going 3x slower than they would with sneakers, and 2x slower than they would with winter boots. [...]
We need to have a nuanced understanding of the world to understand when the situation calls for a specialized tool.